Multi Gpu Training
Taking Advantage of Graph Structure
After seeing the performance improvements of using GPUs to train a model we want to see if we could take advantage of our computational graph structure to use multiple GPUs and parallelize computation. In our particular case the computational graph has two tower-like structures, a convolution, activation, fully connected layer, and activation, over a set of user reviews, and a mirroring convolution over a set of item reviews.
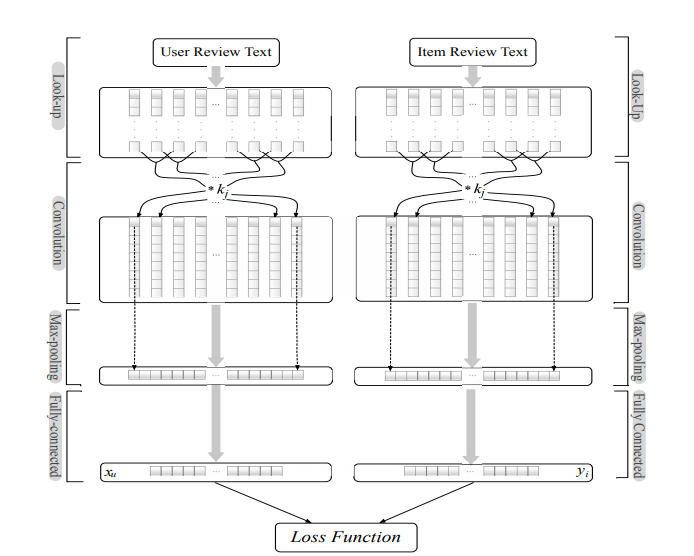
It seems like a model with such structure could easily be parallelized by placing the two tower operations on different gpus.
with tf.device("/gpu:0"):
u_inputs = features[0]
u_inputs = table.lookup(u_inputs)
u_inputs = tf.nn.embedding_lookup(word_embeddings, u_inputs)
user_conv1 = tf.layers.conv1d(
u_inputs,
filters,
kernel_size,
use_bias=True,
activation=tf.nn.tanh,
name="user_conv")
user_max_pool1 = tf.layers.max_pooling1d(user_conv1, 2, 1)
user_flat = tf.layers.flatten(user_max_pool1)
user_dense = tf.layers.dense(user_flat, 64, activation=tf.nn.relu)
with tf.device("/gpu:1"):
i_inputs = features[1]
i_inputs = table.lookup(i_inputs)
i_inputs = tf.nn.embedding_lookup(word_embeddings, i_inputs)
item_conv1 = tf.layers.conv1d(
i_inputs,
filters,
kernel_size,
use_bias=True,
activation=tf.nn.tanh,
name="item_conv")
item_max_pool1 = tf.layers.max_pooling1d(item_conv1, 2, 1)
item_flat = tf.layers.flatten(item_max_pool1)
item_dense = tf.layers.dense(item_flat, 64, activation=tf.nn.relu)
In the code above we used Tensorflow’s with tf.device(...) feature to place our tower operations on different devices. Below we present the average runtime per epoch over five epochs for single-gpu and dual-gpu training.
| Device Placement | Average Seconds/epoch Time |
|---|---|
| Single GPU | 20.455 s |
| Dual GPU | 22.500 s |
We can see above that our model actually took MORE time to train on average when we trained on GPU. This effect is actually common in the deep learning community because GPUs have been optimized so heavily for matrix computations that the time it takes to transfer data between devices slows down processing. We can confirm that this is the actual reason our model slows down by making the model alternate between devices for each operation and see if it slows down further.
with tf.device("/gpu:0"):
u_inputs = features[0]
with tf.device("/gpu:1"):
u_inputs = table.lookup(u_inputs)
with tf.device("/gpu:0"):
u_inputs = tf.nn.embedding_lookup(word_embeddings, u_inputs)
with tf.device("/gpu:1"):
user_conv1 = tf.layers.conv1d(
u_inputs,
filters,
kernel_size,
use_bias=True,
activation=tf.nn.tanh,
name="user_conv")
with tf.device("/gpu:0"):
user_max_pool1 = tf.layers.max_pooling1d(user_conv1, 2, 1)
with tf.device("/gpu:1"):
user_flat = tf.layers.flatten(user_max_pool1)
with tf.device("/gpu:0"):
user_dense = tf.layers.dense(user_flat, 64, activation=tf.nn.relu)
with tf.device("/gpu:1"):
i_inputs = features[1]
with tf.device("/gpu:0"):
i_inputs = table.lookup(i_inputs)
with tf.device("/gpu:1"):
i_inputs = tf.nn.embedding_lookup(word_embeddings, i_inputs)
with tf.device("/gpu:0"):
item_conv1 = tf.layers.conv1d(
i_inputs,
filters,
kernel_size,
use_bias=True,
activation=tf.nn.tanh,
name="item_conv")
with tf.device("/gpu:1"):
item_max_pool1 = tf.layers.max_pooling1d(item_conv1, 2, 1)
with tf.device("/gpu:0"):
item_flat = tf.layers.flatten(item_max_pool1)
with tf.device("/gpu:1"):
item_dense = tf.layers.dense(item_flat, 64, activation=tf.nn.relu)
With this exaggerated device placement we now have an average runtime of 23.021 seconds per epoch, confirming our suspicions! What if we would like more information and to find out exactly how much time is spent transfering data? Lets now take a look at the nvidia gpu profiling tools and see if we can narrow down the time spent transfering.
To run the nvidia gpu profiler simply run the command
nvprof python "DeepCoNN - dual gpu lots of device transfers.py" &> nvidia.txt
This will create a file nvidia.txt containing a summary of GPU operations. After running for our “parallelized towers” model and “exaggerated device placement” we found the following important difference. Below we present the single most costly GPU function call for each of our tested models.
Time(%) Time Calls Avg Min Max Name
# exaggerated device placement
24.53% 13.0696s 94774 137.90us 4.3190us 994.70us [CUDA memcpy PtoP]
# reasonable device placement
20.08% 10.0978s 78292 128.98us 4.3190us 893.33us [CUDA memcpy PtoP]
# single device placement
17.54% 6.92109s 4120 1.6799ms 290.78us 2.7316ms void tensorflow::UnsortedSegmentCustomKernel...
As we can see, the exagerated device placement is causing our model to spend nearly 5% more peer-to-peer data copies, resulting in 3 extra seconds spent simply copying data. On the other hand, when we use a single GPU the majority of time is spent on a tensorflow kernel operation, as expected in a model who’s primary operation is a convolution. This shows that for some models, and I would venture to say most models that fit in single-GPU memory, training times are fastest when training on one GPU.